Ambient Poem Rhythm Game Proposal
Since the last blogging, we had a workshop for MusicVAE, using Jupyter notebook. It is really lovely that the last workshop really fits to my final project concept, so I can save sometime to research and trial and errors.
One thing I figured out was, not only training and generating new pieces, (Even just testing pre-trained models took hours to just generate few sentences!!) I needed to simplified my concept.
I changed to use poem from prose. This makes sense for the concept of listening narration rhythmically. Poems have rhythm and musical elements by nature.
I scraped Poetry Foundation for poems, and they actually do have Listen section as a way to appreciate poetry.
I was thinking about a very ambitious plan such as real-time generating narrative-music, but I guess I need to be satisfied with a small start.
The poem I am gonna use is A Gift for You BY EILEEN MYLES.
- generate the narration.
Wavenet Vocoder (Colab link/VocoderGithub/TacotrionGithub)
Tacotron2 predicts Mel-spectrogram of a text, and WaveNet synthesis a voice based on that. - Nsynth interpolation.
Since I wanted to give a sense of musical piece, I chose NSynth for the interpolation between generated voice and ambient music.



I tried just like the poem lines, but the sound so stiff and strong, so I made lines again based on the waveform of original narration.
It took so much time to generate each line, I tried Nsynth simultaneously.
NSynth 1 [Human Voice || Tibet Singing-bowl || Ibo Drum]
NSynth 2 [Generated Voice || Ocarina sound || Flute Sound]
At the first iteration, I thought low pitch instrumental sounds are really good to hear, but the interpolation result with human voice was a bit monstrous and unpleasant. I changed to high pitch instruments for the second iteration.
Instrument sounds samples below
Ibo drum sample
After these trial, it looks like Nsynth might not be the model I was looking for. What I was looking for was something like Style Transfer for Music.
Using Nsynth interpolates pitch and rhythm also, but I wanted to keep the rhythm and pitch of narration while change the timbre from instruments, or a certain music genre.
While looking for code, I found Wavenet generatef from Mel-spectrogram representation, so it could be interesting generate instrumental sound from mel-spectrogram of narration file. I actually tried to do that, but I was using Jupyter Notebook so I couldn’t access output files.
For the proof of concept, I tired to put the sounds to rhythm game Unity assets. Still I need to manually assign lines to the sound, but it was so interesting that text and sound was kinda synced if I consider them as four-quarter measure music. Since the asset counts the beats, no matter how long or short the line was, each line passed after 4 beats and it looked okay. This can be a new way fo an approach for the next step.
0. Transcript pitch and rhythm of narration with piano transcript tool, and train with that data set. -most doable
1. Reconstruct the narration from Mel-spectrogram presentation to other musical instrument. -most interesting
2. Generate music from Text analysis. - This method doesn’t have any connection to narration, but I can make it musical.
December 13, 2018
Final Project proposal : exploration
google slideMy concept of final project is making an interactive reading experience with intonation-like ambient background sound.
I got the idea from the frustration of reading English text, compared to how I feel so free when I read in Korean.
I got bunch of text to read every week for discussion (as a grad student), and somehow manage to read them all. But what I found in the classes is I totally lost important cases in the text.
Honestly, I got more overwhelmed by the amount of text, rather than focusing on the contents in the text.
And I found a new experience with audio book recently, since making audio book is a very expensive industry I never experienced the full human voice narration for ebook in Korea. I am not sure if I just miss them, but most of audio services for ebooks are just very distraction TTS, it was better not to hear them for me. Using audiobook narration with ebook was quite interesting, it did help me a lot to focus on the text, especially academic texts. The most challenging part of reading second language text is, you need to stop for searching the meaning of words. when you stop again and again, you just lose your focus and it is hard to come back to the line. (There is a research that outside hinderance is the most challenging disturbance against productiveness.) It may sound ridiculous, but you can speak in second language with people without understanding every single words. There is a semantic understanding within the context. Listening audiobook is quite like that.
Even though audiobook was pretty helpful, but I feel hard to focus on reading them for couple of reasons below.
- Reading speed is commonly much faster than listening
- Speed of narration is hard to modify due to the amount of information
- We actually don’t need to hear every single words - It is like we don’t we actually don’t read every single spell of a word, we just see general shape of the word.
That is the reason that I want to make a narration-like ambient music, which doesn’t contain any distinguishable information, but you feel like someone is mumbling next to you.

So how can I achieve the experience? I found a good blog for deep learning models and intonation (mostly about TTS and deep learning) It looks like several approaches available.
- Pairing a sentence + manipulated audio file from narration —> generate mumbling music and show texts accordingly.
= this one is the most straight forward approach, but also has a lot of constraints. How can I pair each word and sound? is there any tool helps with setting data? or should I do that manually? - Get a score of narration and pair each score to the texts.
= this will be more music piece like approach, and seems doable. I guess this will be like rhythm game. - Existing models seems appropriate to my projects: Sample RNN, Wave net, Lyrebird(?)
Melody RNN
Generating Long-Term Structure in Songs and Stories, 2016(referenced Composing Music With Recurrent Neural Networks,2105 and Neural Machine Translation by Jointly Learning to Align and Translate,2014)
Basic RNN
input :
a one-hot vector of the previous event , the label was the target next event.
event :
-note-off (turn off any currently playing note)
-no event (if a note is playing, continue sustaining it, otherwise continue silence)
-note-on event for each pitch (which also turns off any other note that might be playing)
Lockback RNN
new inputs:
-events from 1 and 2 bars ago —>(mirrored or contrasting melodies)
-whether the last event was repeating the event from 1 or 2 bars before it —>(repetitive or non-repetitive state.)
-the current position within the measure
Step 1: [0, 0, 0, 0, 1]
Step 2: [0, 0, 0, 1, 0]
Step 3: [0, 0, 0, 1, 1]
Step 4: [0, 0, 1, 0, 0]
new labels:
-The label to repeat the event from 1 bar ago.
-The label to repeat the event from 2 bars ago.
—>his allows the model to more easily repeat 1 or 2 bar phrases without having to store those sequences in its memory cell.
Attention RNN
Neural Machine Translation by Jointly Learning to Align and Translate
[an encoder-decoder RNN
the model uses attention to look at all the encoder outputs during each decoder step.]
outputs from the last 𝑛n steps when generating the output for the current step.
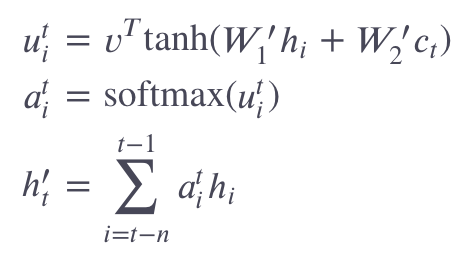
Step 1: [1.0, 0.0, 0.0, 1.0]
Step 2: [0.0, 1.0, 0.0, 1.0]
Step 3: [0.0, 0.0, 0.5, 0.0]
𝑎𝑡𝑖 =[0.7, 0.1, 0.2]
Step 1 (70%): [0.7, 0.0, 0.0, 0.7]
Step 2 (10%): [0.0, 0.1, 0.0, 0.1]
Step 3 (20%): [0.0, 0.0, 0.1, 0.0]
ℎ′𝑡 =[0.7, 0.1, 0.1, 0.8]
The ℎ′𝑡 vector is concatenated with the next step’s input vector and a linear layer is applied to that concatenated vector to create the new input to the RNN cell.
This helps attention not only affect the data coming out of the RNN cell, but also the data being fed into the RNN cell.
Encoding
melodies_lib.Melody format (-2 = no event, -1 = note-off event, values 0 through 127 = note-on event for that MIDI pitch)
Twinkle Twinkle Little Star
--primer_melody="[60, -2, 60, -2, 67, -2, 67, -2]"
Thoughts
Total new transition
Text + Accent —> Musical RNNs = ?
November 15, 2018
Anis Haron - Audio Palimpsest
This might not be symphonic piece, but it is an interesting project in a way of aesthetic and mechanism.
Audio Palimpsest is a hacked cassette recorder, interacting with audience by its IR distance sensor. According to the comment, the recorder wind or rewind the tape according to the approach or receding of audience.
Since the recorder is not only playing the tape but It is overwrite or play the tape, (I couldn’t figure out how they decide which.) the installation records the environmental sound of the site unexpected way, and generates sound.
If you ask me about whether we can tell this as music or just mere sound, I can definitely say this is music. Actually it seems like the artists added some way to make musical sound beside recoding the environmental sound only. September 13, 2018