tweet reader
For expressive interaction, I made a chrome extension that reads tweets that I expend the card.
Here's the video of it. Check the code from GitHub.
Referenced from Speak Selection of Chrome extension examples.
It was the first attempt to use chrome extension, so I just made it as easy and quick, but I think I could push through to make it more expressive.
I tried to use Twitter API for the first time, but it is only for subscribing the authorized account. BeautifulSoup/Puppeteer could make the work easier, but I am not sure it also applies to already open window. As far I understood, it is more for automated scrapping. Therefore, I used vanilla javascript to access the tweet contents.
-Now my twitter account is set in Korean. I might affect the way it parses the tweets.
-I am using the basic Chrome TTS engine, but I guess I can make the voice more expressive by using other engines. (Watson expressive SSML again/or changing the rate/pitch/volume.
Left or Right
0. GOAL
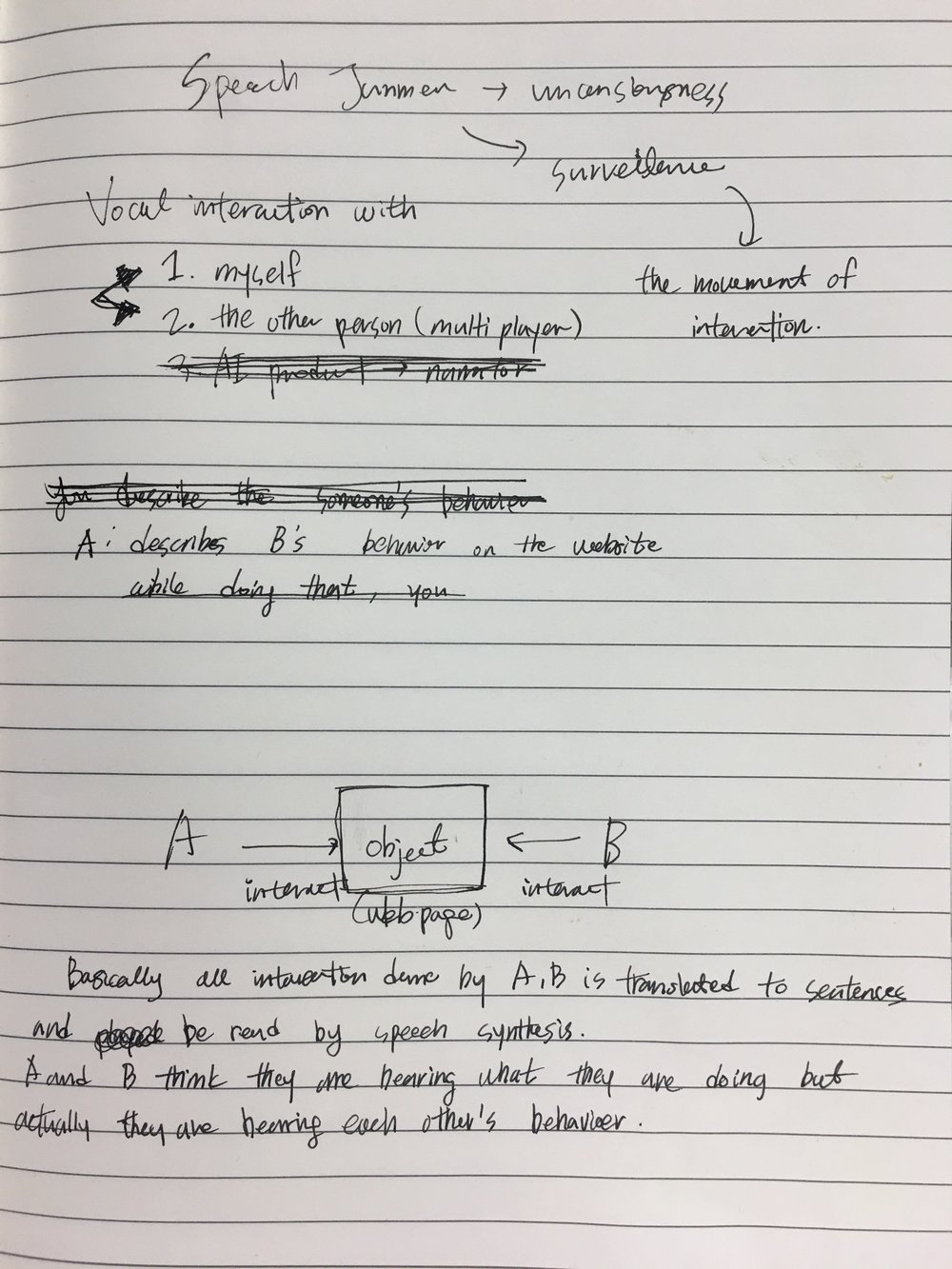
This project started with the simple idea to combine two classes projects together: Dynamic Web Development and Expressive Interaction - Voice. The key requirements are 0. network communication 1. use VUI for that. So I and Phil come up with the idea that making a multiuser game using voice interaction. The key concept that we settled was let users interact with their voice at the same time, even though the gameplay experience is not quite operated or delivered.The picture in my mind was - a bunch of people is shouting to the game nearby, together or separately, and the narration helps /hinder the gameplay. I wanted to realize the mess that all the people shouting and hearing each other, it's a bit participatory performance.
1. PERSONA
There were references that inspired us. Basically, the game targets users sitting in the same place as the best situation, so I can document it as a performance. All users have laptops and use the default mics as input devices. The game will play narrations also, so the voice from other users and the narration will be interruptive inputs together.Twitch Plays Pokémon: multi-user interaction to control one object together.
Last Man Standing: Multiuser interaction using the same objects, but separately.
clickclickclick.click: web-based interaction idea and narration persona.
Stanley Parable: narration persona.
Stranger than fiction: narration persona.
Portal GLaDOS: synthetic narration.
2. VOICE
The narrator persona:-male vs. female: Since most of the authoritative narration are using the male voices, I am interested in trying female authoritative voices.
-synthetic vs. voice acting: using voice actor would be easier to deliver paralanguage (sigh, gasps, throat clearing, mhm..), but using synthesized voice for the experiment purpose also interesting.
So the voice will be a synthetic, female voice that has authoritative, sarcastically humorous, joking personality but makes you feel inhumane somehow (she knows that she doesn't have a physical body in the real world.)
It would be great to show some expressions also(like Watson expressive SSML), but there are not many voice synthesis engines that have expression features together. If I cannot express emotions naturally, rather an artificial sound voice would be better. (Users will excuse the hidden emotion expression.)
Ultimately, it would be perfect to make a neutral-female sound synthetic voice that has emotional expression.
3. INTERACTION FLOW
4. SCRIPT
5. USER TESTING - FURTHER STEP
During the classes, Expressive SSML was the most impressive voice synthesis. I decided to use this as the narrator.

Scraped tweets with the keywords left and right. #Left and #Right was much stronger, but I need to parse the hashtags out, so I just used left and right... (now I think I should refine texts more..)

March 23, 2018
Project Proposal
1. Goal
: make a web, asynchronous experience for multiple users, about behavior jamming. 2. User
: Indie game players who are familiar with web-based interactions.3. Find your Voice
: A female voice that is authoritative, but gentle at the same time. Humorous / sarcastic personality4. Dialog flow/ interaction flow
clickclickclick.click
February 21, 2018
Redundant Eliza
Speaking to VUI was always awkward, no matter which application/service they are. In fact, Siri is the only service that I have used so far. Maybe it could be the reason for avoiding speaking in front of people that I am the youngest one in a big family. For any reason, I have avoided giving information to the public, especially in English.
That awkward feeling continued when I assembled AIY kit. Testing the command on the floor, while everybody is listening to me was not easy. We can find that kind of situation with a real person in real life also. The awkward feeling when you consistently overlap while the other person is speaking and both of them keep yielding to speak first each other.
A, B: so...
A: you go first.
B: No, you can talk first.
(infinite loop)
Maybe this does not happen in other cultures, but I guess it is pretty common to see in Korea, where appreciates polite attitude in conversation.
Anyway, this overlap makes you awkward to talk since you are interrupted. Hearing something while you are trying to talk something makes your brain jammed.
Speech-Jamming Gun in Public Spaces.
So I come up with an idea that making a chatbot that maximizes awkwardness in the conversation. The personality of voice is arrogant and sarcastic, so it keeps pretending to miss the conversation, answers in a very sarcastic way and does not do its job.

1. The program needs to record the user's command.
2. It can play the recorded sound (hopefully right back) to the user so the user cannot keep talking.
3. Even if the user successes to deliver the command, the AI answers in a sarcastic way.
Hope it was true to me also... Teaching AI how to be sarcastic is totally the easiest thing ever
I started with the example codes in AIY source. Tell a long story short, I failed. These are what I figured out after 6 hrs programming.
1. Using assistant APIs doesn't support to manage which answers that the AI gives.
- in this case, other people made their own chatbot, but I wanted to 'hack' the chatbot while keeping the structure of it. (That's the reason I needed to use either of gRPC or google assistant library.)
2. To record and playing back, multi treading is required. When I saw assistant_library_with_button_demo.py, multi treading looks possible, but could not figure the way to do it.
So what I did is just make it keep repeating to the user to make them annoyed, and randomly denies to 'assist' them.
As the result, it sounds rather like ELIZA than contemporary AIs we have.
It supposed to turn off and show the youtube video when the user says 'awkward', but the processor was too slow and showed the link a bit l made me embarrassed.
Hers is the code.
February 16, 2018